
正确率仅15%,GPT-4远不如人类?
正确率仅15%,GPT-4远不如人类?
当前,大型语言模型(LLMs)或许是通用人工智能(AGI)得以实现的“最优解”。
然而,尽管大模型在流利性和知识广度方面貌似已接近人类水平,但评估它们的挑战日益突显。随着大模型的迅猛发展,一些传统基准已经失效。因此,新的测评基准亟需制定。
近日,来自 Meta、HuggingFace 和 AutoGPT 的研究团队共同提出了一个用于测试通用 AI 助手的基准——GAIA,该基准提出了现实世界中需要一系列基本能力的问题,如推理、多模态处理、网络浏览和通用工具使用熟练技能。
研究团队表示,这些问题在概念上对人类来说非常简单,但对大多数大模型来说,却很有挑战性:一个直观的数据,人类回答这些问题的成功率为 92%,而即使是带有插件的 GPT-4 仅有 15% 的成功率。这与近年来大模型在法律或化学等需要专业技能的任务中表现优于人类的趋势形成了鲜明对比。
相关研究论文以“GAIA:A Benchmark for General AI Assistants”为题,已发表在预印本网站 arXiv 上。

值得注意的是,GAIA 的理念偏离了当前 AI 基准的趋势,即瞄准对人类来说越来越难的任务。研究团队认为,AGI 的出现取决于系统能否在此类问题上表现出与普通人类似的鲁棒性。
通用AI助手基准:与真实世界互动
随着大模型能力的提升,现有的评估基准变得越来越难以满足新模型的挑战,传统的基准测试很快就会被这些新模型超越。
在尝试将大模型变成通用助手的过程中,目前的评估方法相对滞后。现有的评估主要依赖于封闭系统、特定 API 调用或者重新使用现有的评估数据集。然而,这些方法通常在封闭环境中进行,可能评估的是助手学习使用特定 API 的程度,而不是在真实世界互动中更通用的能力。
相比之下,GAIA 采用了与真实世界的互动作为评测基准,并不限定可能的 API。还有其他一些方法也在探索通用助手的评估,但它们与 GAIA 的核心区别在于它们更关注当前模型的能力,而不是未来的进展。
据论文描述,GAIA 是一个测试 AI 系统通用助手问题的标准,旨在避免 LLMs 评估中的各种问题。GAIA 包含由人类设计和标注的 466 个问题。这些问题主要是文本形式的,有时还包含一些文件,比如图像或电子表格。问题涵盖了各种通用助手应用场景,包括日常个人任务、科学问题和一般知识。问题设计成只有一个简短而正确的答案,因此很容易验证。使用 GAIA 只需要向 AI 助手提示这些问题,并附带相关的证据(如果有的话)。

另外,使用 GAIA 评估 LLMs 只需要具备向模型提问的能力,也就是说,需要能够访问 API。研究人员在向模型提问之前使用了一个前缀提示。为了方便提取答案,他们还在前缀提示中规定了一种格式。
随后,他们对 GPT4 进行了评估,包括有插件和没有插件的情况,还评估了以 GPT4 为后端的AutoGPT。目前,GPT4 需要手动选择插件,而 AutoGPT 能够自动进行这个选择。
结果表明,GAIA 允许清晰地对能力强的助手进行排名,同时在未来的几个月甚至几年中仍然有很大的改进空间。
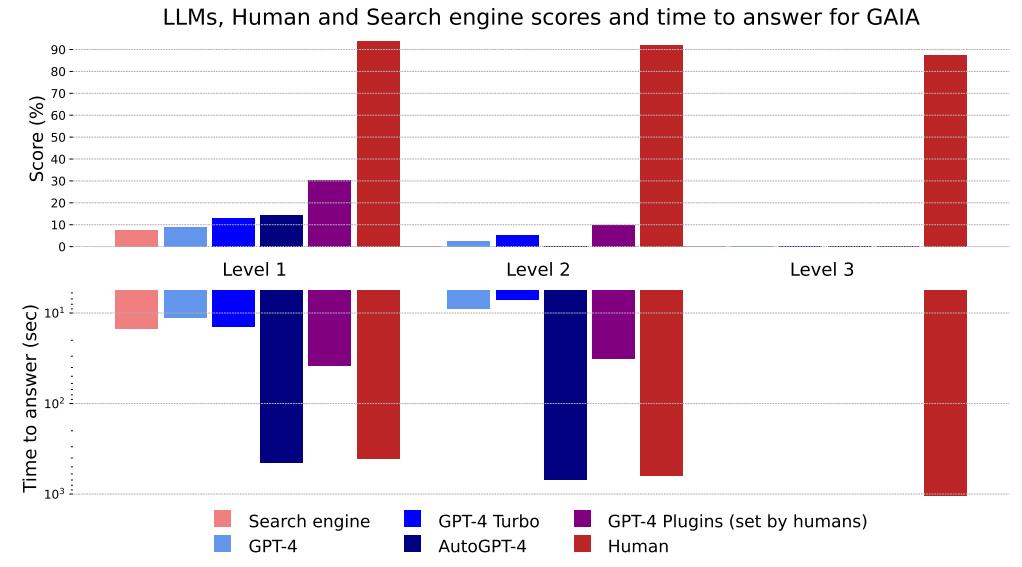
从图中可以看出,人类的网络搜索在 Level 1 方面表现良好,但在更复杂的查询上效果不佳,而且速度稍慢。与没有插件的 GPT-4 相比,使用插件的 GPT-4 在提高答案准确性和执行计划方面表现更好。AutoGPT-4 自动使用工具,但在 Level 2 和甚至 Level 1 方面的表现令人失望,可能是由于其依赖 GPT-4 API 的方式。总体而言,与使用插件的 GPT-4 合作的人类似乎在分数和时间之间找到了最佳的平衡。
评估 AI 助手潜力的第一步
GAIA 的出现让我们重新思考当前和未来 AI 系统评估的范式。
封闭在 API 后面的模型可能会随着时间的推移而改变,这意味着在不同时间点进行的评估可能无法复制或重现。另外,问题可能会更加复杂,因为像 ChatGPT 插件这样的工具和它们的功能会定期更新,而不是通过 ChatGPT 的 API 进行访问。
由于研究人员在评估模型性能时通常依赖于真实世界的基准,而这些基准可能会随着时间的推移而改变,所以实现可重现性可能会变得更加困难。然而,GAIA 对于生成随机性的处理是鲁棒的,因为它只关注最终的答案,即只接受一个正确的响应进行评估。
此外,相较于规模更大但多项选择问题的数据集,GAIA 注重问题质量而非数量。GAIA 的持续发展有望成为更全面评估 AI 系统泛化能力和稳健性的关键组成部分。
GAIA 任务可能涉及调用各种模块来完成,比如图像分类器可能返回错误的标签。有些人可能会觉得这样的评估有些含糊,因为 GAIA 看待系统为一个整体,而不是把错误归因于系统的子部分,比如网络浏览或视觉模块。然而,将 LLMs 与其他工具紧密结合以完成所有任务可能不是可持续的方法。未来的模型可能会在语言模型和其他能力之间更加集成,如视觉语言模型。
GAIA 的目标是评估整个 AI 系统,而不仅仅是特定的架构标准。更广泛地说,对于复杂生成的自动、事实和可解释的评估一直是生成式 AI 中的一个长期难题。
目前的评估方法可能存在一些限制,未来可能需要更复杂的方法,比如结合多模态系统,通过对图像进行复杂的序列修改,并在自然语言中提出明确问题的方式来改进生成模型的评估。
尽管深度学习在各领域取得了进展,但全自动化目前仍面临无法预测的失败,如自动驾驶汽车的挑战。解决 GAIA 问题需要全自动化,但这可能导致社会经济格局的改变,存在技术所有者主导价值捕获的风险。
另外,GAIA 也存在一些局限。首先,GAIA 无法评估不同路径通向正确答案的情况。论文作者建议未来考虑人类和模型评估,以弥补这一缺陷。
此外,由于 OpenAI 的 API 未提供详细工具调用日志,当前只评估了具有工具访问权限的最强大的语言模型。研究团队希望在未来能够在开源领域添加其他具备足够工具使用能力和日志记录的模型。
为了创建现实且易于使用的基准,需要两轮注释,第一轮由注释者设计明确问题,第二轮由两位独立注释者回答问题并排除歧义,尽管这过程彻底,仍可能存在歧义。
最后,GAIA 的一个重大限制在于它缺乏语言多样性:所有问题只能用“标准”英语提出,而且许多问题主要依赖于英语网页。
因此,GAIA 只是评估通用 AI 助手潜力的第一步,不应视为它们成功的绝对证明。
参考链接:
https://arxiv.org/abs/2311.12983
作者:闫一米
编辑:学术君
-

- 美国有多少人口梳理(美国的整个市场很大吗)
-
2024-04-08 19:13:25
-

- 家养水母吃什么食物(人工饲养水母的方法和注意事项)
-
2024-04-08 19:11:19
-

- 蓝瓶青瓷汾酒多少钱(汾酒青花蓝瓶)
-
2024-04-07 09:31:14
-

- 金剑南24k价格多少钱(金剑南24K多少钱)
-
2024-04-07 09:29:08
-

- 湖北关公坊价格表(湖北关公坊酒52度价格表)
-
2024-04-07 09:27:02
-

- 红酒开瓶器开瓶盖示意图(开瓶器的支点等示意图)
-
2024-04-07 09:24:56
-

- 合肥 白酒贸易招聘(合肥市酒水销售代表招聘信息)
-
2024-04-07 09:22:51
-

- 洋酒为什么要兑饮料(洋酒兑饮料度数会低吗?)
-
2024-04-07 09:20:45
-

- 心酒钻石多少钱一瓶(心酒砖石36度)
-
2024-04-07 09:18:39
-

- 微信卖啤酒如何宣传语(微信啤酒碰杯)
-
2024-04-07 09:16:33
-

- 厦门葡萄酒品牌(厦门葡萄酒进口商)
-
2024-04-07 09:14:28
-

- 散酒多少钱一斤(纯粮散酒多少钱一斤)
-
2024-04-07 09:12:22
-
- 杏花玉液42度成箱(杏花玉液酒53度多少钱)
-
2024-04-06 20:40:26
-
- 绍兴黄酒多少钱(绍兴黄酒多少钱)
-
2024-04-06 20:38:20
-

- 酒吧卖的是什么东西(酒吧卖娃娃是什么意思)
-
2024-04-06 20:36:15
-
- 金徵酒多少钱一瓶(金徽酒的价值)
-
2024-04-06 20:34:09
-

- 嘉世伯价格(嘉世伯公司)
-
2024-04-06 20:32:03
-

- 会稽山花雕酒价格(会稽山花雕酒价格国营绍兴东凤酒厂)
-
2024-04-06 20:29:57
-
- 海之蓝棉柔42度多少钱一瓶(海之蓝绵柔型42度多少钱一瓶)
-
2024-04-06 20:27:52
-
- 古井三十年原浆价格 古井原浆酒30年的价格是多少钱
-
2024-04-06 20:25:46
 脱贫标准 人均收入2020,脱贫标准
脱贫标准 人均收入2020,脱贫标准 换乘地铁需要重新买票吗,换乘地铁需不需要重新买票?
换乘地铁需要重新买票吗,换乘地铁需不需要重新买票?